Nikolaos Gkizis Chatziantoniou describes his internship with the CDHU working on the projects SweMPer and Quantifying Culture
During my internship at the Centre for Digital Humanities at Uppsala University, I worked both on digitizing physical books for the project “Swedish Medical Periodicals – (SweMPer)” as well as pre-processing, cleaning, and labeling images for the project “Quantifying Culture”.
Regarding the digitization project SweMPer, we had to create digital copies of Medical Periodicals, as a part of enriching medical history archives. The method used was destructive scanning, which is much faster and cost-efficient than other methods, partially sacrificing the book’s integrity but not the contents. The spine of the book is removed with a guillotine and the pages are scanned, digitized, and transcribed using Optical Character Recognition (OCR). The remaining physical pages are archived in case we need to rescan them.
Book scanner and paper guillotine
The “Quantifying Culture” project is an effort aimed at using Artificial Intelligence (AI) within the cultural context, as well as reviewing existing methods. The task here was to train an algorithm that automatically classifies gender in a collection of digital images. During the data collection stage, we used a web scraper to download images from the World Culture Museum to create the datasets. Afterward, I manually cleaned and grouped the images in order to create the training data for the algorithm. Additionally, I had to experiment with ideas on how to automate parts of the process and think about solutions to the problem of overlapping datasets.
My involvement in those two projects gave me a clearer view of the definition of a digital humanist and its work within the cultural sector. Solving practical problems, automating processes using code, and ultimately thinking about the implications of the methods used regarding costs, and social or ethical issues that may arise, are all parts of the digital humanist’s identity.
In more detail, regarding the digitization project SweMPer, I had to think about the implications of fast digitization versus a slow more detailed one, in relation to funding, available resources, and the project’s timespan. As for the Quantifying Culture project, I got a glimpse of the inner workings of the creation of an algorithm that classifies gender. I realized that the most important part of the process is actually not the algorithm itself but rather finding the right training data, removing biases, consulting experts regarding the classification of certain ethnic groups, and thinking about the implications of choosing a binary model to label the images.
The role of the digital humanist is not only working around the digitalization of culture as a coding humanist. This role becomes clearer when a project lacks social sensitivity, is focused on the data instead of the human factor, or removes diversity in favor of clear and uniform results. The digital humanist involved in those projects reintroduces those elements to the research and changes the focus towards a more human and socially aware AI.
In the following post, Dr. Michaela Vance writes about her pilot project undertaken with the CDHU–an author attribution study of Frances Brooke’s libretto, Marian.
About six months ago, in a moment of unbridled optimism, I set out to investigate whether the second, performed version of Frances Brooke’s libretto Marian was actually and truly written by her, or if the changes to the same could be reasonably assumed to be the work of a second (unknown) writer. Since then, I have come to have a greater appreciation of the difficulties involved in attributing authorship to short texts. In the following, I will give a short account of a workshop on the subject, hosted and organized by the Centre for Digital Humanities at Uppsala University, following my successful pilot project application to the same.
In preparation for the workshop I made a corpus of texts of a similar era and genre, against which we could run the two librettos in question. These included some of Brooke’s earlier texts such as the libretto to Rosina, the tragedies Virginia and Siege of Sinope, and sections of her novels. In addition, I included a selection of texts by other writers, such as Dibdin’s Shepherdess of the Alps, O’Keefee’s The Wicklow Mountains, and Bickerstaff’s Love in a Village, and Hanna Moore’s tragedies Percy and Fatal Falsehood. An initial problem was the OCR quality of these texts – firstly, because there exists no OCR .txt copy of the manuscript of Marian, and secondly, because the automatic OCR renderings of old printed texts are often far from ideal. However, I managed to make a decent OCR copy of the manuscript version of Marian with the help of Transcribus, and Ekta Vats made an brilliant OCR copy of the printed version of Marian. The rest of the texts were found at the excellent open source project ECCO-TCP, which hosts a large collection of SGML/XML-encoded texts.
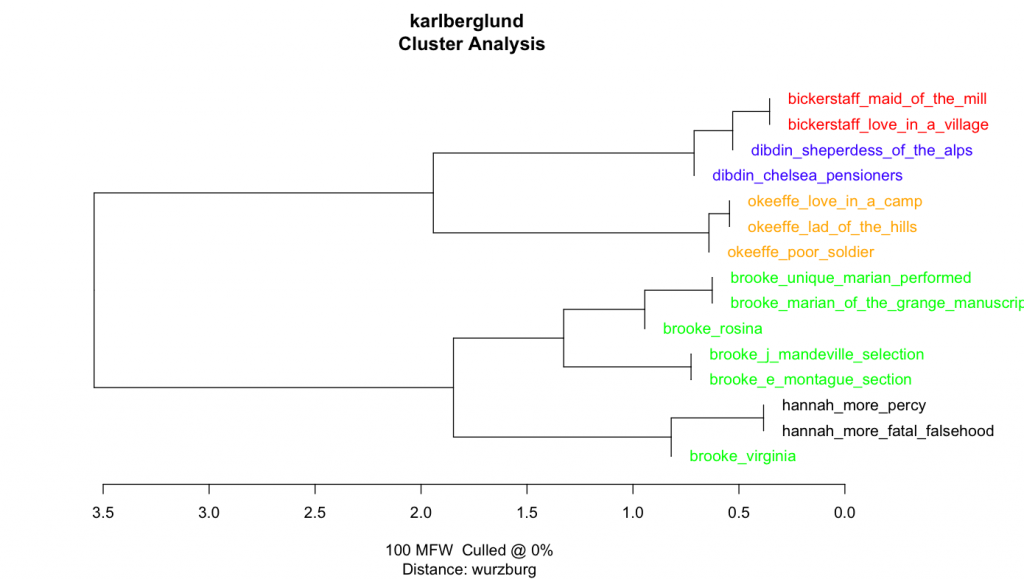
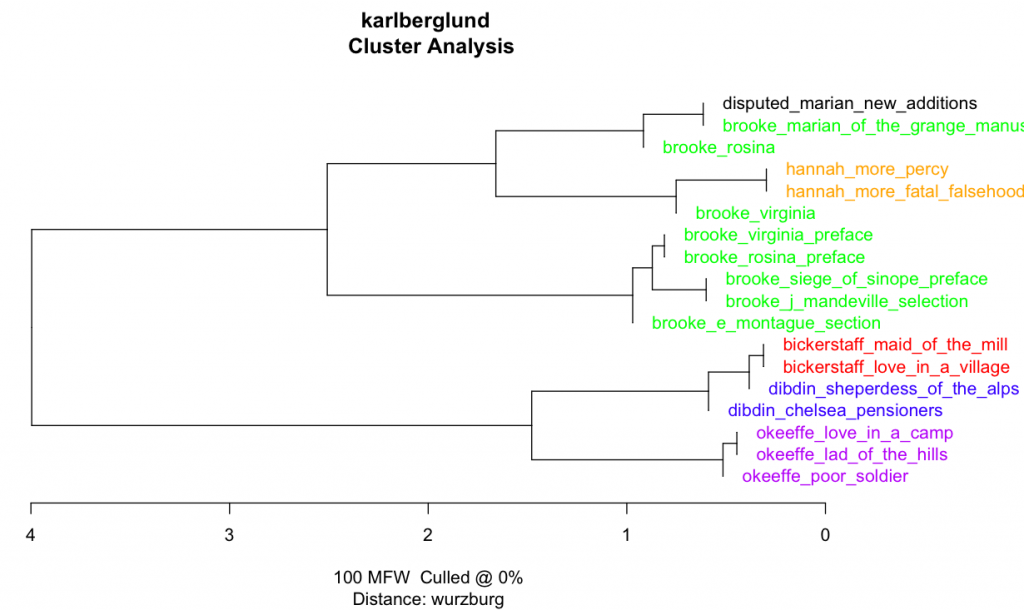
Having addressed the OCR issues in the week before the workshop, project coordinator Karl Berglund, research engineer Marie Dubremetz and I set out to get some initial results in Stylo (run in R) when we met at Uppsala. Trying first Cosine Delta, the texts clustered based on stylometric similarity. As can be seen in Figure 1 this worked rather well in many ways, but it did not give enough of an indication that Marian differed to any substantial degree from Brooke’s other texts in terms of authenticity. We moved on to the second method, “rolling classify”, but here we ran into issues repeatedly due to the text in question being too short. Intriguingly, both methods cluster the texts by women (Brooke and More) together, while the texts written by men are quite clearly clustered on a separate branch.
Figure 1Figure 2
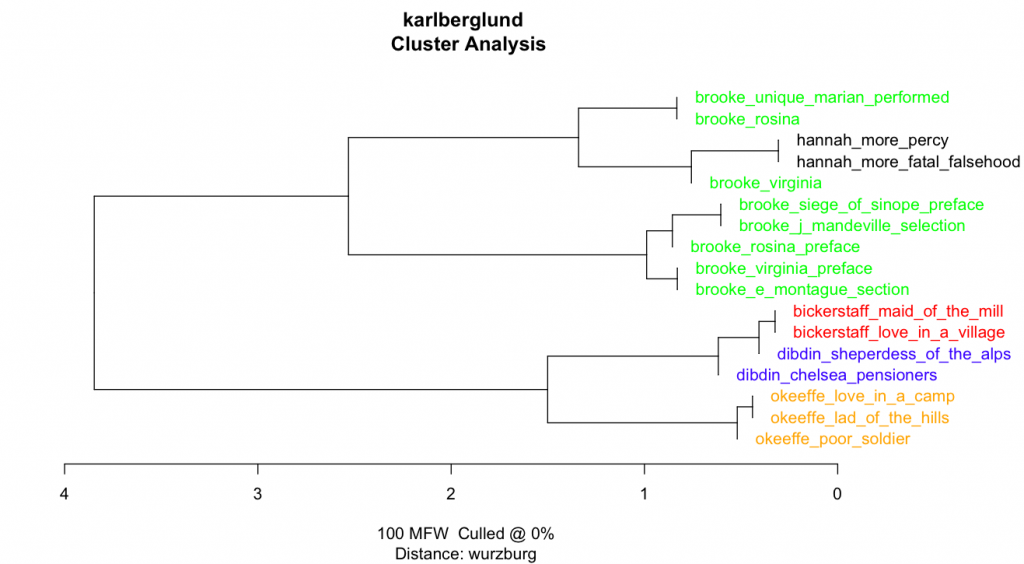
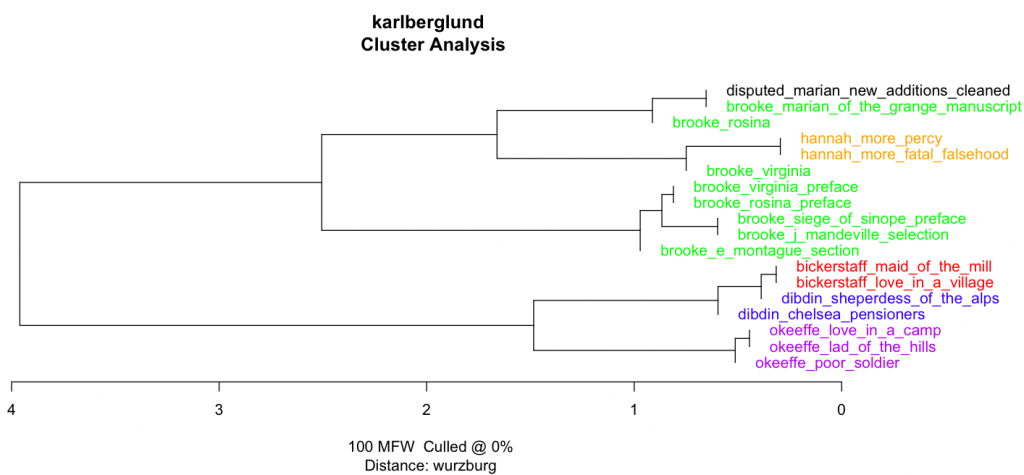
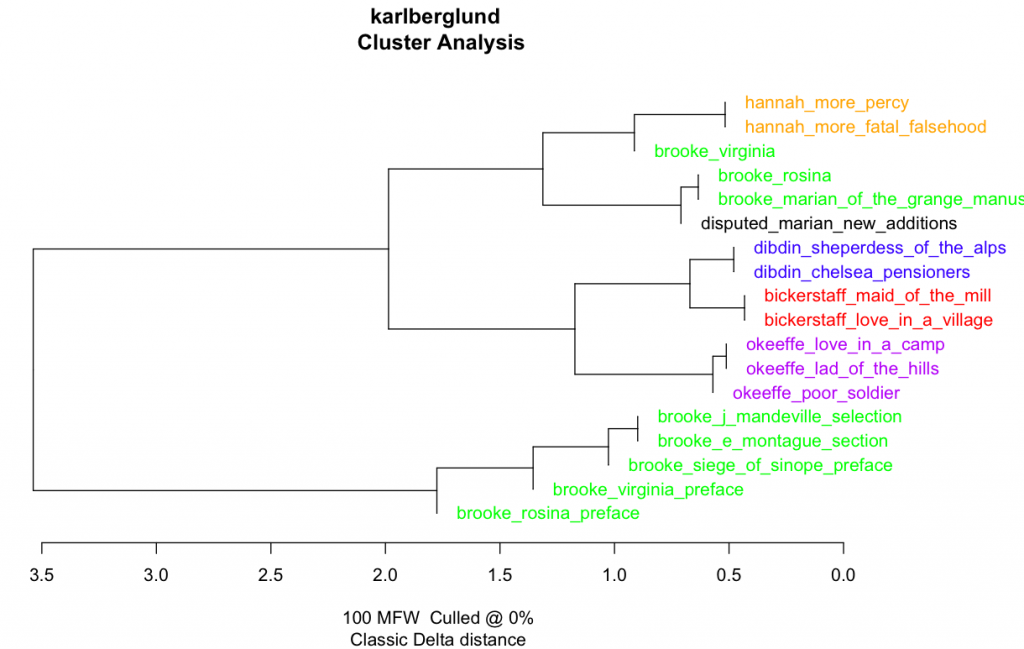
In the next step, we tried to tackle the issue of the similarity of the two librettos by distilling the later version of Marian into a document that only contains the changes – a kind of super edition here called “disputed Marian new additions cleaned”. Having tried a variety of programs to help me spot and separate changes to the newer version of Marian, I finally gave up and did it by myself by just placing the versions next to each other and marking each change by hand. Given the very limited length of the texts and the fact that the librettos were interspersed with songs, we had low hopes of getting clear results. Nevertheless, as can be seen in Figure 3-5, some interesting results came out of the new Stylo effort. First, we can see that the variation with which the texts are grouped depending on method is quite notable, but also, that the women writers continue to consistently group together. Second, in figure 4 the distilled document with all of the isolated changes to Marian is further away from the manuscript version of Marian than Rosina is. This is intriguing, as it indicates greater variety of style between the two versions of Marian than between two entirely different librettos by Brooke. Caution needs to be exercised, however: the texts cluster on the level of author probability rather than text-specific features as such, and both versions of Marian and Rosina are situated on the same branch. Getting less ambiguous results would require further testing, with even greater attention to stylistic, syntactic, and morphological data, especially as we cannot speculate as to who might have made the changes to the original manuscript, and therefore do not have access to a reliable selection of comparison texts.
Figure 3Figure 4Figure 5
I went in to the project feeling fairly certain that Brooke had not made the changes to Marian herself, but now, even with such uncertain results, I find myself more open to the idea that she did indeed make those changes. Part of this has to do with the level of attention I paid to the smallest details of the two scripts as I prepared them for the Stylo experiments. The method encouraged me to consider aspects of the changes that I had not really registered before – an incidental but positive aspect of stylometry that, somewhat ironically, brings it back to the methods that predates the computer. I hope that I will be able to discuss the changes and what they might mean for how we understand Brooke’s ideas about class and genre in a different outlet in a not-too-distant future.
If you would like to read more about stylometric methods and short texts, I recommend checking out “The Dynamiter” project at http://thedynamiter.llc.ed.ac.uk/ and three articles, Hirst and Feguina’s “Bigrams of Syntactic Labels for Authorship Discrimination of Short Texts” in Literary and Linguistic Computing (2007), Gorman’s “Author identification of short texts using dependency treebanks without vocabulary” in Digital Scholarship in the Humanities, and Corrinne Harol, Brynn Lewis and Subhash Lele’s “Who Wrote It? The Woman of Colour and Adventures in Stylometry” in Eighteenth-Century Fiction.
The Neoliberalism in the Nordics programme, funded by Riksbankens Jubileumsfond, met at the Sigtuna Foundation in February 2022 with 20 participants from the Nordic countries and from similar research programs in the Netherlands and Germany. For three days, research presentations were interspersed with methodological discussion and joint work on research timelines, source texts, and stakeholder-networks.
Karl Berglund, Research Coordinator CDHU
Karl Berglund, Research Coordinator for the Center for Digital Humanities Uppsala, was invited to the meeting. Karl gave an introductory lecture on digital conceptual history and text analysis, which was an excellent basis for our further discussions. Neoliberalism in the Nordics is not based on digital text analysis, unlike for example the exciting Market Language project run by Leif Runefelt and Henrik Björck. Instead, a key point in our work is that the history of neoliberalism is multifaceted, spans several different historical stages, and over a large number of mutually different materials, actor-constellations, and genres.
The program is also based on extensive archival work, for example in the business archives that exist in Sweden and Denmark. Analyzing this complex and heterogeneous repertoire digitally entails great challenges, as neither materials nor languages are uniform and comparable. In the initial phase of the program, we therefore opted out of digital methods and the main method in the program is archival research and concept history. At the same time, there are good opportunities to build a smaller corpus to help analyze the larger issue, and it might also be possible to use, for example, the digital parliamentary material, or daily press material, which is available for all the Nordic countries to make trans-Nordic comparisons. Challenges, however, include comparability over time and across language boundaries.
Another difficulty is that the word ‘neoliberalism’ as such is not very useful as a keyword; digital analysis needs to focus on understanding, for example, constructions such as market-freedom, or natural law-growth. Since none of the participants in the program are experts in the field of digital methods, it was an invaluable help to talk to Karl, and during the spring we are considering the possibility of initiating a pilot project with the Center for Digital Humanities.
Programmet Nyliberalism i Norden, finansierat av Riksbankens Jubileumsfond, möttes på Sigtunastiftelsen med 20 deltagare från Norden och från liknande forskningsprogram i Nederländerna och Tyskland. I tre dagar varvades forskningspresentationer med metoddiskussion och gemensamt forskningsarbete kring tidslinjer, källtexter, och aktörs-nätverk.
Till mötet hade vi bjudit Karl Berglund från Centrum för Digital Humaniora i Uppsala. Karl gav en introduktionsföreläsning till digital begreppshistoria och textanalys, som var en utmärkt grund för våra fortsatta diskussioner. Nyliberalism i Norden är, till skillnad från exempelvis det spännande Marknadens språk-projektet som Leif Runefelt och Henrik Björck driver, inte baserat på digital textanalys. En huvudpoäng i vårt arbete är att nyliberalismens historia är mångfacetterad, spänner över flera olika historiska skeden, och över en stor mängd inbördes olika material, aktörskonstellationer, och genrer. Programmet bygger också på ett omfattande arkivarbete, exempelvis i de näringslivsarkiv som finns i Sverige och Danmark. Att analysera denna komplexa och heterogena repertoar digitalt innebär stora utmaningar, då varken material eller för den delen språk är enhetliga och jämförbara. I inledningsskedet av programmet valde vi därför bort digitala metoder och den huvudsakliga metoden i programmet är arkivforskning och begreppshistoria. Samtidigt finns det goda möjligheter att bygga mindre korpus som hjälp att analysera den större frågeställningen, och det skulle eventuellt också vara möjligt att använda exempelvis det digitala riksdagsmaterial, eller dagspressmaterial, som finns för alla de nordiska länderna för att göra transnordiska jämförelser. Svårigheter är är jämförbarhet över tid och över språkgränser. Ett problem är också att ordet ‘nyliberalism’ som sådan inte är särskilt användbart som sökord, utan digital analys behöver inriktas på att förstå exempelvis konstruktioner som marknad – frihet, eller naturrätt – tillväxt. Eftersom ingen av deltagarna i programmet är expert inom området digitala metoder var det en ovärderlig hjälp att prata med Karl, och vi funderar under våren på att initiera ett pilotprojekt med Centrum för digital humaniora.
CDHU is a member of three research infrastructure consortia that were awarded by the Swedish Research Council (Vetenskapsrådet): SveDigArk, led by Archaeology at UU, HumInfra (led by HumLab at Lund University), and Infravis (via the Centre for Image Analysis at Uppsala University and led by Chalmers University of Technology). In the following post, Director of the centre, Associate Professor Anna Foka describes the particulars of CDHU’s involvement in large national infrastructure consortia and the importance for developing humanities and social sciences infrastructure at a national level.
Uppsala has a brilliant tradition in historical-philosophical studies since at least 17th century, and the Heritage Law saw the formation of the first antiquities department here, the predecessor to the National Heritage Board of Sweden (Riksantikvarieämbetet). The first professor of Archaeology in Sweden was also at Uppsala, Oscar Almgren, in 1914. So, it should not come as a surprise that Uppsala is becoming involved in such national infrastructure projects. But why is this happening now?
One factor is the maturity of resources; there is now a Centre for Digital Humanities at Uppsala University, awarded with 30 million kr for the next five years and supported across disciplinary domains (HumSam, TekNat) and faculties (HistFil) which additionally supports these infrastructure initiatives from within by providing both socio-technical resources and providing support and access to a supercomputer (Uppmax) and a stable open cloud infrastructure (Central IT).
This means that we can now financially support these nationally awarded infrastructures. The SveDigArk application led by our extraordinary colleagues at Uppsala Archaeology is supported by us via a Geographic Information Systems (GIS) expert. We are further a part of HumInfra: the National Digital Humanities Infrastructure led by Humlab at Lund University; there our role as CDHU and within our module is to support artificial intelligence (AI) training, methods and tools for the humanities and social sciences, as well as to connect to European such infrastructures from the perspective of information science and information organisation. Our mission is develop our AI Laboratorium within CDHU. For InfraVis: The National Scientific Visualisation infrastructure led by Chalmers in Gothenburg, we are tapping onto another excellent resource: the Centre for Image Analysis at Uppsala University to experiment with the latest trends in scientific visualisation methods and tools.
A second point is that we, academics, researchers, scholars, are currently more aware of how fast-pacing technology leads to organisational change, which then leads to new scientific discoveries and vice-versa. Having the opportunity to study those phenomena at a national level is also a consequence of technological development.
A final factor is how we, global academics of the socially and environmentally challenging 2020s, seem to comprehend the importance of collegiality and collaboration for global impact. Researchers in any discipline are now commonly called upon to correspond to research questions that are not necessarily compartmentalised in disciplines or strictly bound to one geographical region, but are grounded in the complexities and relations of the real world and are meant to have global impact—in other words, to be both transformative and generative for humanity and society. This is what CDHU hopes to inspire, beyond digital methods and tools that we can all parse and process.
For research in the long run, these three projects mean that, across humanities and social sciences within UU and in Sweden more generally, we will together pioneer a number of trending digital methods and tools for research: namely Artificial Intelligence (such as image processing, natural language processing, machine learning) as well as Data Science, GIS, and Scientific visualisation more generally. It also means that we as researchers will be given the possibility to discuss these incredible new technologies within national clusters and complement each other’s findings, thus bringing Sweden to the forefront of international research.
We are happy to begin Autumn 2021 by welcoming several staff members to the CDHU! The research engineers, coordinators, and staff at the Centre for Digital Humanities work together offering consultation, practical, and technical support for world-class research that integrates digital methods and tools.
Our staff can support different stages of the research process—from research design to obtaining data, statistical analysis, data visualization, and more.
Research Engineers at CDHU have expertise in a variety of technical skills and knowledge sets, such as coding and data science, to statistical analysis, machine learning, and natural language processing.
Read below to learn more about our research engineers and coordinators:
Ekta Vats Research Engineer
Ekta Vats
Research Engineer– AI and Image Processing
I am a Research Engineer at the Centre for Digital Humanities where I work as an image analysis and data science expert. I am interested in investigating how research-oriented AI solutions can be adopted in real-world applications in the field of Humanities and Social Science. At CDHU, I would like to help scholars and researchers gain an understanding of AI and data-driven methods, teach relevant courses, share knowledge through creative workshops, and also support their infrastructure needs.
By training, I am a PhD in Computer Vision, and have worked as an AI Scientist at Silo AI Stockholm, and prior to that, as a researcher at the Center for Image Analysis at Uppsala University. I am also working as a Computer Scientist AI/HTR at Folkrörelsearkivet for Uppsala Län on the Labour’s Memory project, which aims at making large scale material from The Swedish Trade Union Confederation-sphere (from the 1880s until today) available and accessible.
My research interests broadly span computer vision, image processing, machine learning and handwritten text recognition, with applications in Digital Humanities and Social Sciences. I like to challenge myself with different types of problems, and also from different domains, and have expertise in deep learning and data science. My most recent work includes large-scale image analysis and machine learning for digital palaeography, using computerised methods to automatically analyse Swedish medieval charters.
Mudassir Imran Mustafa Research Engineer
Mudassir Imran Mustafa
Research Engineer-Infrastructure
I am a design researcher with a multidisciplinary background (i.e., Information Systems, Computer Science and Software Engineering). As a design researcher, I have the curiosity and desire to learn new things, see new perspectives and be involved in creating a better world. My research interests include the identification of quality characteristics and formulation of design principles to continuously preserve, improve, and adapt the research infrastructure in an academic research context to allow such infrastructure to be maintained and to evolve more efficiently.
At the Centre for Digital Humanities (CDHU), I would like to help scholars and researchers gain an understanding of how to use the research infrastructure available (e.g., UPPMAX/SNIC) and manage research data. I hope to use my interdisciplinary research expertise, particularly about understanding and designing digital research infrastructures and digital practices, to offer guidance and support for the various interdisciplinary research projects in the Humanities and Social Sciences.
More generally, I am very excited to build a sustainable research infrastructure at the CDHU, I believe this is especially important to the Humanities and Social Sciences.
Marie Dubremetz
Research Engineer-AI and Natural Language Processing
I began my studies with a Bachelor’s degree in Classics and Humanities, but following my Master and PhD in Computational Linguistics, I transitioned from a literary background to a more technical profile.
As a natural language processing specialist, I hope to help researchers in their use of tools to process textual data–novels, news articles, historical texts… Through python, bash scripts, and many other tools, corpora will give the best of themselves. For ideas of what I can do and how I can help, you can have a look at my list of projects on my website: www.mariedubremetz.com .
Through my career I have witnessed how bringing technology and programming to humanist profile can foster extraordinary research. Whether one is an anthropologist or philosopher, lawyer or historian… humanists cultivate a meaningful approach that the innovation field needs to benefit from. I envision the center as a competitive, inspiring, but also as an open and welcoming place. Transitioning from literary studies to programming is exciting but not easy, especially if you are alone in this process. I will be there to help.
Karl Berglund Research Coordinator
Karl Berglund
Research Coordinator
My background and PhD is in literature, more specifically oriented towards the sociology of literature, a sub-field that has for a long time applied quantitative methods on literary materials. When digitisation started to take off in the 2000s, it opened up completely new possibilities for systematic literary analyses on a larger scale. I understood that I needed to learn some basic programming and statistics to be able to master these digital methods myself, and this road led me to the digital humanities.
As a scholar, I am currently PI in a research project on contemporary bestselling fiction called “Patterns of Popularity”. Among other things, I track audiobook consumption patterns from datasets derived from Storytel, along with a colleague at computational linguistics. I am also the founder and coordinator of the Uppsala Computational Literary Studies Group (UCOL).
At CDHU, I am a research coordinator, which means that I try to help HumSam researchers that need technical and/or methodical support in different ways, mostly by being a link to our engineers. I manage our pilot project support calls, plan workshops and seminars, and am currently in the process of planning a PhD course in “Cultural Analytics”, to be held in the spring 2022. I am also the main organiser of the DHNB 2022 conference that will be hosted at Uppsala University in March next year.
I believe that computational methods will be a standard element in the HumSam research toolbox of the future. My vision for CDHU is that we aid HumSam researchers at UU both by providing technical expertise, and by teaching them to do things themselves (and thereby generate interest to learn further). For me, the latter is especially important as I hope it can empower future generations of HumSam scholars.
Clelia LaMonica Communications Officer
Clelia LaMonica
Communications Officer
My background is in general linguistics, with a more recent focus on English language and use. In my research I have explored statistical methods for analyzing mixed qualitative and quantitative data related to language perception and production, as well as discourse analysis of certain registers such as Legal English, Business English, and teaching English for Specific Purposes. The interdisciplinarity of these topics led me to seek methods of visualizing and combining different forms of data, such as corpus research, network analysis and GIS, and I then became involved in the GIS for Language Studies (LanGIS) group, as well as Digital Humanities here at Uppsala.
My focus at CDHU as communications officer is to connect with and expand our network, both internally among the faculties, centres, departments, and scholars, and externally among international universities, organisations, and research programmes. I would, overall, like for CDHU to communicate a unique profile for academics looking to explore digital methods and techniques, as well as the infrastructure we have available.
My hope is that researchers who have not previously explored digital methods, or who are uncertain what ‘digital humanities’ actually encompasses, reach out to the Centre and expand their digital horizons! The Centre is a fantastic resource that has something for everyone—individual researchers and large international programmes alike—so I look forward to working in Uppsala and across Sweden, as well as with our international partners, to expand the Digital Humanities infrastructures and support that exist for scholars in the Humanities and Social Sciences.
About the DH blog
An outlet for new ideas, research presentations and other outputs from the Digital Humanities Uppsala research network.










Recent Comments